با داده ها چه می توان کرد؟ 15- پردازش لجستیک
هنگامی که پاسخ در باره متغیر مورد نظر ما که قرار است آن را تحلیل و پیش بینی کنیم، آری یا نه باشد، یعنی یک انتخاب دو گانه، از پردازش لجستیک استفاده می کنیم.
به عبارت دیگر پردازش لجستیک Logistic Regression به ما این امکان را می دهد که با استفاده از داده ها در متغیرهای گوناگون مشخص کنیم نتیجه نهایی در باره متغیری که پیشگویی آن مقصود ماست، چیست.
با یک مثال مشخص، موضوع را بررسی می کنیم. فرض کنید که ما داده های ثبت شده یک بانک در باره شرایط مالی و شخصی افرادی که تاکنون کارت اعتباری گرفته اند را در اختیار داریم. در این مثال ما اطلاعات در باره میزان درآمد فرد، مبلغ بدهی و وضعیت تحصیلی او که آیا دانشجو است یا نه را داریم و همینطور می دانیم که آن افراد در بازپرداخت بدهی قصور داشته اند یا نه. توجه دارید که بررسی این موضوع که آیا یک فرد توانایی بازپرداخت را دارد و یا نه یک پاسخ دو گانه آری یا نه است و حتی احتمال ورشکستگی شخص مورد نظر اگر از درصدی بیشتر باشد، بانک اعتبار در اختیار او قرار می دهد یا نه.
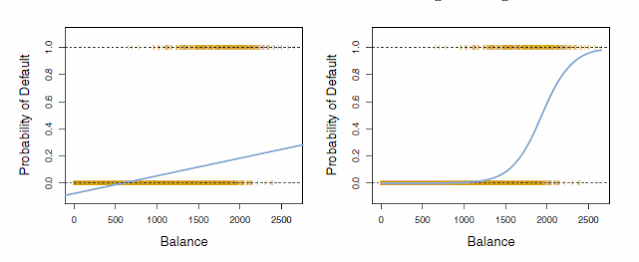
در این حالت (لجستیک) ما بر خلاف پردازش خطی که داده ها در متغیرهای تعیین کننده (مثال تاثیر متغیرهای تبلیغات تلوزیون، رادیویی و روزنامه بر میزان فروش) که در قسمتهای گذشته بررسی کردیم، مشخصا عدد و رقم نیست، اگرچه تعیین احتمالات همواره عددی است بین صفر و یک. در اینجا ما در جایگاه یک تحلیگر استخدام شده توسط بانک وام دهنده صراحتا می خواهیم تصمیم بگیریم که مثلا به درخواست یک متقاضی کارت اعتباری جواب مثبت بدهیم یا منفی.
بدون آنکه بخواهیم بطور عمیق وارد فرمولهای ریاضی بشویم، بیاد داریم که در پردازش خطی، فرمول مورد استفاده برای تعیین میزان شیب (ضریب) هر متغیر X که بر روی Y تاثیر داشت بدینگونه بود:
Y ≈ β0 + β1X
در پردازش لجستیک این فرمول به این صورت است. توجه داشته باشید که (p(X همان Y است.


بعدا در همین قسمت نحوه بدست آوردن این ضریب را با هم مرور می کنیم اما همانطور که در بالا می بینید، ضریب متغیر بدهی بسیار پایین است. اگر این ضریب و نقطه آغازین Intercept را در فرمول بالا قرار دهیم، مثلا با فرض آنکه بدهی یک فرد 1000 است، احتمال عدم بازپرداخت بدین صورت می شود:

نتیجه بدست آمده نشان می دهد که احتمال عدم پرداخت وام توسط فردی که 1000 دلار بدهی بر روی کارت اعتباری دارد، تقریبا نیم درصد است. حال بانک مربوطه می تواند با توجه به سیاستهای خود به درخواست کننده کارت اعتباری جواب مثبت یا منفی بدهد. به عنوان مثال اگر سیاست بانک اعتبار دهنده در مورد اعطای اعتبار به افرادی که احتمال باز پس ندادنشان زیر 5 درصد باشد، فرد مورد نظر ما در فرمول بالا می تواند کارت اعتباری دریافت کند. توجه دارید که ما فقط یک متغیر یعنی میزان بدهی را در این فرمول محاسبه کردیم.

حالا اگر با پایتون و پانداز داده ها را محاسبه کنیم، ضریب سه متغیر ذکر شده به این صورت زیر در می آید:



در این داده ها در زیر ستون دانشجو بله یا نه ثبت شده است. در محاسبه پردازش لجستیک ما باید این داده ها را ابتدا به صفر و یک (دوگانه عددی) تبدیل کنیم والا قادر به محاسبه نخواهیم بود. پایتون و پانداز نمی توانند جواب بلی یا نه را محاسبه کنند. همچنین باید توجه داشته باشیم که پس از تغییر این داده ها به صفر و یک، هر کدام معرف چه نتایجی هستند. یعنی آیا 1 نماینده دانشجو بودن است یا صفر؟

اکنون نوبت خواندن (استفاده) داده ها در نوتبوک است:

همانگونه که در بالا اشاره کردم، باید جوابهای بلی و خیر را به صفر و 1 تغییر دهیم. اینکار را از طریق کدی که در بالا زرد شده است انجام می دهیم. توجه کنید همزمان دو ستون جدید نیز ایجاد می کنیم. همانگونه که می بینید عدد 1 معرف دانشجو بودن و عدم بازپرداخت است.

تعداد داده های ثبت شده 10000 است. اطلاعات دیگری نیز در جدول بالا مثل تاریخ و زمان محاسبه، نام مدل، R2 و غیره قابل مشاهده است.
این کد به شما احتمالات (درصد احتمال بین صفر و 1) را، همانگونه که ما با قرار دادن عدد 1000 دلار در فرمول بدست آوردیم، ارائه می دهد:
result.predict(df)
این کد را پس از آنکه ضریبها را بدست آوردید، خودتان امتحان کنید.
جدول پایین نیز ضریبها و دیگر اطلاعات را با توجه به محاسبه دو متغیر دیگر نشان می دهد:

- اطلاعات مربوط به این بخش و قسمتهای دیگر در باره پانداز، بیشتر برگرفته از کتاب Python for Data Analysis, Data Wrangling with Pandas, NumPy,and IPython چاپ دوم از انتشارات اورایلی است که توسط Wes McKinney، خالق پانداز، نوشته شده است.

Comments
Post a Comment